Kita tidak bisa berharap server akan baik-baik saja selamanya. Oleh karena itu, saya membangun sistem Observability menggunakan Prometheus dan Grafana untuk memantau kesehatan server secara real-time.
Namun, dashboard yang cantik tidak berguna jika kita harus memelototinya 24 jam. Di artikel ini, saya akan membagikan perjalanan teknis saya mengonfigurasi Automated Alerting ke Telegram, termasuk bagaimana saya menangani insiden saat Stress Testing.
Arsitektur Sistem
-
Metrics Collector: Node Exporter (Linux Metrics).
-
Time-Series DB: Prometheus.
-
Visualisasi & Alerting: Grafana.
-
Notification Channel: Telegram Bot.
Menyiapkan Telegram Bot
Pada tahap ini kita akan membuat Bot Telegram untuk menampilkan pesan alert.
-
Buat Bot Baru:
-
Buka Telegram, cari @BotFather.
-
Ketik
/newbot. -
Ikuti instruksi (beri nama bot & username).
-
Simpan HTTP API Token yang diberikan. Nantinya ini kita gunakan untuk proses menghubungkan Grafana dengan Telegram.
-
-
Cari ID Telegram:
-
Cari bot @userinfobot.
-
Klik Start. Salin angka ID yang muncul.
-
-
Aktifkan Bot:
-
Cari nama bot yang baru kita buat tadi.
-
Klik START (
/start). Tanpa langkah ini, bot tidak punya izin mengirim pesan ke kita.
-
Konfigurasi Contact Point di Grafana
Agar Grafana bisa terhubung dengan Telegram kita perli daftarkan Bot tadi ke Grafana.
-
Masuk ke Dashboard Grafana.
-
Buka menu Alerting Contact points.
-
Klik + Add contact point.
-
Isi konfigurasi:
-
Name:
Telegram-Alert -
Integration:
Telegram -
Bot API Token: (Paste token dari langkah 1)
-
Chat ID: (Paste ID dari langkah 1)
-
-
Validasi: Klik tombol Test di pojok kanan atas Send test notification.
-
Jika pesan masuk: Koneksi Sukses.
-
Jika error: Cek kembali Token/ID dan pastikan sudah
/startbot-nya.
-
-
Klik Save contact point.
Membuat Alert Rule
Di sini kita mengajarkan Grafana cara mendeteksi bahaya.
-
Buka menu Alerting Alert rules.
-
Klik + New alert rule. Beri nama
High CPU Load. -
Setting Query (Kotak A):
-
Pilih datasource: Prometheus.
-
Mode: Code.
-
Masukkan Query (Mendeteksi penggunaan CPU):
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[1m])) * 100)
-
-
Setting Logika (Kotak B – Reduce):
-
Jangan gunakan
Mean(Rata-rata) jika ingin deteksi instan. GunakanLast. -
Function:
Last. -
Input:
A.
-
-
Setting Ambang Batas (Kotak C – Threshold):
-
Input:
B. -
IS ABOVE:
60(Bunyi jika CPU di atas 60%). -
Klik Set as alert condition.
-
Mengatur Notifikasi
Agar notifikasi tidak telat atau malah menjadi spam, kita perlu mengatur “Traffic Light”-nya.
-
Buka menu Alerting Notification policies.
-
Edit Default policy.
-
Pastikan Contact point mengarah ke
Telegram-Alert. -
Tuning Timing (Agar Responsif):
-
Group wait:
10s(Hanya tunggu 10 detik sebelum kirim). -
Group interval:
1m(Update info setiap 1 menit). -
Repeat interval:
5m(Ingatkan lagi setiap 5 menit jika masalah belum kelar).
-
Template Pesan Alert
Pesan bawaan Grafana sangat teknis. Kita ubah agar mudah dibaca manusia.
-
Kembali ke Contact points Tab Notification templates.
-
Buat template baru bernama
telegram_bersih. -
Isi dengan kode berikut:
{{ define "telegram_bersih" }} {{ if gt (len .Alerts.Firing) 0 }} 🔥 <b>ALARM BAHAYA (FIRING)</b> {{ range .Alerts.Firing }} <b>Server:</b> {{ .Labels.instance }} <b>Pesan:</b> {{ .Annotations.summary }} ------------------------------ {{ end }} {{ end }} {{ if gt (len .Alerts.Resolved) 0 }} ✅ <b>SUDAH SEMBUH (RESOLVED)</b> {{ range .Alerts.Resolved }} <b>Server:</b> {{ .Labels.instance }} {{ end }} {{ end }} {{ end }} -
Simpan Template.
-
Edit Contact Point
Telegram-Alertlagi, di bagian Optional Telegram settings > Message, panggil template tadi:{{ template "telegram_bersih" . }}
Stress Testing
Sistem belum teruji tanpa simulasi bencana.
-
Siapkan Terminal VPS dan HP Anda.
-
Jalankan perintah Stress Test (Membebani CPU):
ab -n 5000 -c 100 http://43.xx.xx.238/2025/12/31/test/
-
Observasi:
-
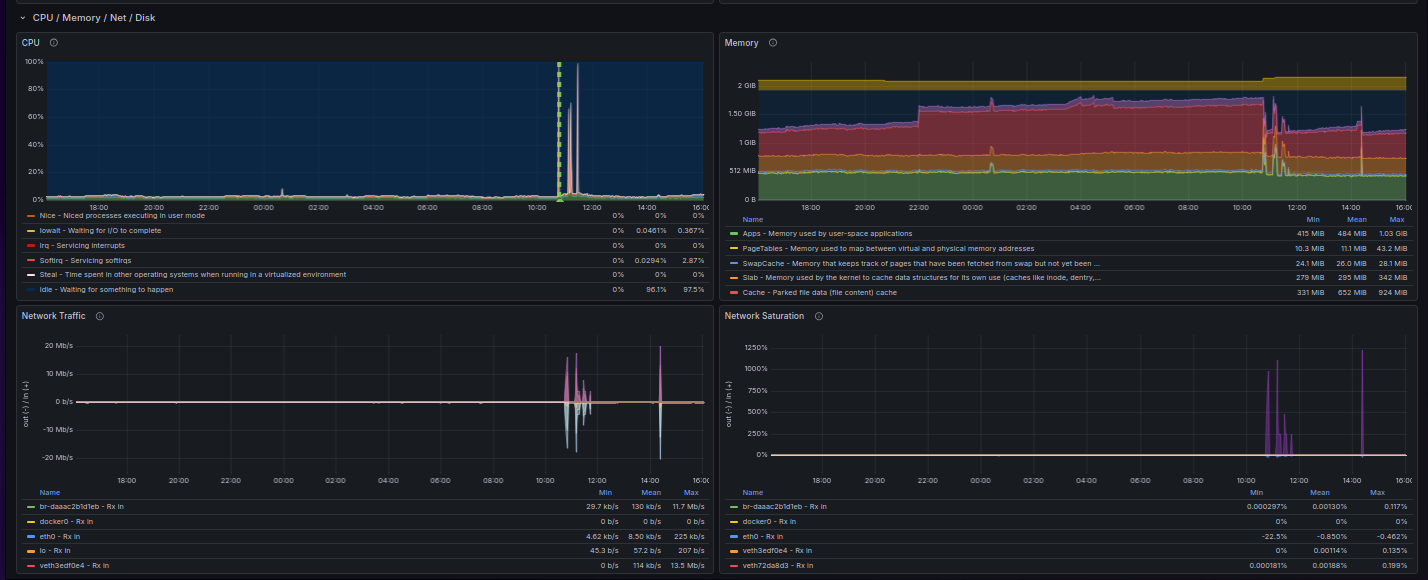
Menit ke-0: CPU naik di Dashboard.
-
Menit ke-1: Status Alert di Grafana berubah jadi Pending (Kuning) lalu Firing (Merah).
-
Notifikasi Masuk: “🔥 ALARM BAHAYA…”
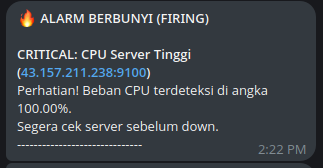
-
-
Hentikan script (
Ctrl+C). Tunggu beberapa menit.-
Notifikasi Masuk: “✅ SUDAH SEMBUH…”
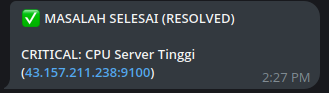
-
Kesimpulan
Dengan konfigurasi ini, saya berhasil menurunkan Mean Time To Detect (MTTD) insiden server. Sistem ini bekerja otomatis 24/7, memungkinkan tim SRE untuk tidur nyenyak dan hanya bangun ketika ada masalah yang benar-benar nyata (Critical).